Yildan yilga insoniyat hosil qiladigan, uzatadigan va saqlaydigan maʼlumotlar miqdori ortib bormoqda. Maʼlumotlar qanchalik koʻp boʻlsa, ularni boshqarish shunchalik qiyin kechadi, shu jumladan, tez yuborish, ishonchli arxivlash, xakerlardan himoya qilish ham. Koʻplab muammolarni fayllarni saqlash va hujjatlar bilan ishlash uchun moʻljallangan bulutli xizmatlar yordamida hal qilish mumkin. N + 1 “Акронис-Инфозащита” hamkorligida data-markazlar saqlash xavfsizligi va maʼlumotlarni qabul qilish tezligini qanday kafolatlashini aytib beradi.
Insoniyat buncha maʼlumotni qayerdan olgan?
Insoniyat tomonidan hosil boʻlayotgan maʼlumotlar hajmi dahshatli tezlik bilan oʻsib bormoqda. IDC kompaniyasi hisoblariga koʻra, 2018-yildan 2025-yilgacha dunyodagi barcha maʼlumotlar hajmi 33 zettabaytdan 175 zettabaytgacha oʻsadi (bir zettabayt — 1021 bayt).
Soʻnggi 20 yil ichida maʼlumot hosil boʻlish tezligi ikki barobarga oʻsdi, demak, hozirgi oʻn yillikning oʻrtasida insoniyat tarixdagidan koʻra koʻproq maʼlumot hosil qilishga muvaffaq boʻldi. Joriy asr oxiriga borib dunyodagi maʼlumot miqdori toʻrt yottabaytdan oshib ketadi (bir yottabayt — 1024 zettabayt).
Foydalanuvchilar oʻz qurilmalarida matnlar, fotografiyalar va videolar saqlamoqda, ish xatlari yozmoqda va ijtimoiy tarmoqlarga kontent joylamoqda. Hootsuite maʼlumotlariga koʻra, 2019-yilda besh milliarddan koʻp mobil foydalanuvchilar boʻlgan va bu hisob oshib bormoqda.
Soʻnggi 9 yil ichida ijtimoiy tarmoq foydalanuvchilari ham naq 3,5 milliardga yetdi. Facebookʼning oʻzini oladigan boʻlsak, unda 2 milliarddan ziyod foydalanuvchi bor va har kuni ulardan 800 milliondan koʻpi nimagadir layk bosadi.
Har daqiqada odamlar YouTubeʼda 4 milliondan ortiq video tomosha qiladi va Instagramʼga 45 mingdan koʻp rasm joylashadi. Vaholanki, ulardan tashqari boshqa koʻplab ijtimoiy tarmoq va messenjerlar mavjud.
Har bir izlangan soʻrov saqlab qoʻyiladi va data-sferaga muayyan miqdordagi maʼlumotlarni qoʻshadi, Googleʼning oʻziyoq sekundiga 40 000 dan ortiq soʻrovni qayta ishlaydi. Bunga raqamli platforma va xizmatlar — taksi, musiqa, ob-havo, chipta va mehmonxonalar, pitsa va bank xizmatlari ham oʻz hissasini qoʻshadi.
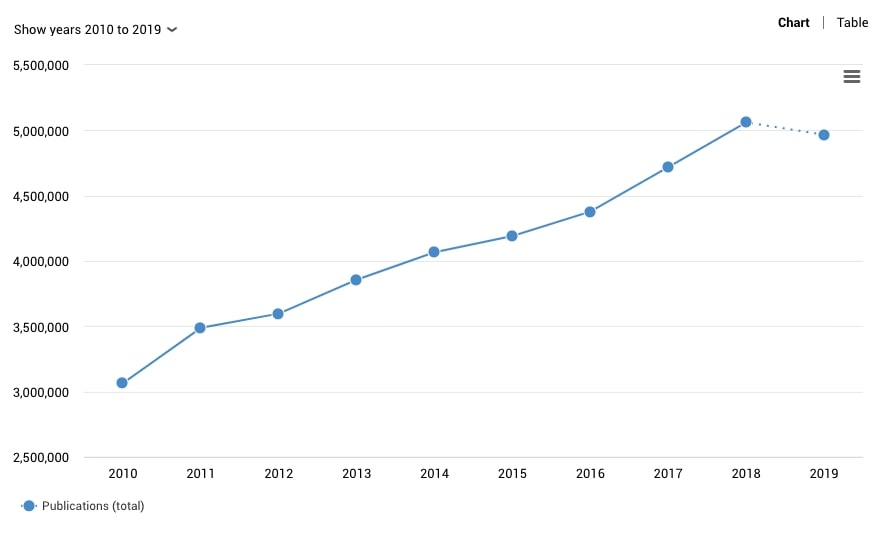
Ilmiy tadqiqotlarning oʻzi alohida masala. Olimlar — tilshunoslar va biologlardan tortib arxeolog va astrofiziklargacha — ilmiy maqolalar yozadi, kitoblarni raqamlashtiradi va eng ahamiyatlisi, oʻlchovlar va tajribalar natijalari haqidagi maʼlumotlarni yigʻadi. Genetik tadqiqotlarni olaylik: birgina genomga 350 gigabaytgacha hajm ketishi mumkin.
Nihoyat, nisbatan yangi maʼlumot manbai — “buyumlar interneti”. Ishlab chiqaruvchilar aqlga kelgan barcha qurilmalarga datchiklar oʻrnatmoqda — elektronika arzon, ixcham va energo-samarali boʻlib bormoqda.
Bundan tashqari, oldinlari maʼlumotlar har ehtimolga qarshi saqlangan boʻlsa, hozir sunʼiy intellekt (SI) rivoji va neyron tarmoqlar ustiga qurilgan ilovalarning keng tarqalishi bilan har qanday maʼlumot qaysidir maʼnoda qiymatga ega boʻlib qoldi: neyron tarmoqlarga oʻrgatishda qancha koʻp maʼlumot ishlatilsa, bu algoritmlar shuncha aniq va yaxshi ishlaydi. Shunday ekan, har qanday yigʻilgan maʼlumot pul turadi va yangi xomashyo sifatida sotilmoqda.
Maʼlumotlarni saqlashning muammo va xavflari
Odamlar maʼlumotlarni turli format va turli qurilmalarda saqlaydi, natijada “koʻchirish muammolari” yuzaga keladi. Endi diskovodlar yoʻq, noutbuklar CDlardan qutuldi, yangi telefonlarga eski sim-kartalar tushmayapti. Shuning uchun texnikani doimiy almashtirib turishni yaxshi koʻradiganlar fotosurat va boshqa ish fayllarini koʻchirishda qiyinchilikka uchramoqda.
IDC hisoblariga koʻra, 2025-yilga borib dunyodagi barcha maʼlumotlarning 60 foizini tijorat korxonalari ishlab chiqaradi. Ular mijozlar haqidagi maʼlumotlarni, bank maʼlumotlari va buxgalteriya hisobi boʻyicha hujjatlarni yigʻadi. Bularning hammasi yangi maʼlumot tizimiga oʻtish, buxgalteriya topshiriqlari va hisob tartiblarining qayta tuzilishi jarayonida saqlab qolinishi kerak.
Fayllar boshqa filiallardagi xodimlar va ofisdan tashqarida ishlayotganlar uchun ham foydalanishga tayyor boʻlishi kerak. Versiyalar dolzarbligini taʼminlash lozim, masalan, xodimlar hujjatlarni birgalikda oʻzgartirayotganda va jismonan — bosib chiqarilgan qogʻoz va elektron tashuvchilar orqali harakatlanayotgan maʼlumotlarni sinxronlashtirishayotganda.
Korxonalarda oddiy foydalanuvchidan koʻra koʻproq hujjatlar yigʻiladi, maʼlumotlar miqdorining oʻsishi bilan yangi xavflar paydo boʻladi, chunki katta miqdordagi maʼlumotlar bir qancha tashuvchilarda saqlanadi. Har bir element yetarlicha ishonarli boʻlgan taqdirda ham uning ishdan chiqish ehtimoli yoʻq emas.
Bunday elementlar yetarlicha — aytaylik, ming yoki oʻn mingga yetganda va ulardagi qaydlar bir yildan beri olib borilayotgan boʻlsa, ehtimoli past boʻlgan xatoliklar ham koʻzga tashlanaveradi. Bunday hollarda har bir elementning ishlashini tekshirib turadigan va ular buzilib qolganda maʼlumotlar egasiga kerak boʻladigan emas, balki oldindan xabar beradigan diagnostika tizimi kerak.
Katta hajmli maʼlumotlarni tarmoq orqali yuborishning qiyinchiliklari
Ham yuridik, ham jismoniy foydalanuvchilar baʼzida katta hajmli maʼlumotlar — mediafayllar, hujjatlar arxivi, mashinali oʻrganish modellari kabilarni uzatishlari kerak boʻlib qoladi. Bu ish doim ham oson boʻlavermaydi.
Masalan, qora tuynuk “fotosurati”ni yaratish jarayonida shunchalik koʻp maʼlumot yigʻilganki, ularni internet orqali uzatgandan koʻra qattiq disklarda jismonan tashishga kamroq vaqt ketardi.

Baʼzida maʼlumotni yuklab olish va koʻchirishning vaqt va moliyaviy sarfi nisbatan yaqin boʻladi. Yana bir boʻlgan voqea: Xitoydan AQShga 1,5 terabayt maʼlumot uzatish kerak edi. Great Firewall of China tufayli ulanish sekin va beqaror edi, shu tufayli fayllarni qattiq diskda olib oʻtish osonroq kechardi. Ikkala tanlov ham juda yomon edi, chunki bunaqa hajmli maʼlumotni yuklab olish narxi qattiq disk narxiga teng kelardi, ammo diskni manzilga yetkazish ham kerak edi.
1980-yillardan qolgan hazilda aytilganidek, shosseda ketayotgan yuk mashinasi tashiyotgan kompyuter lentalarining oʻtkazuvchanligini mensimaslik kerak emas: oʻshanda internetga tezligi sekundiga 1200/1400 bit boʻlgan telefon modemlari orqali ulanishardi. Undan buyon uzatish tezligi bir necha yuz million barobarga oʻsdi (hozirgi oʻrtacha tezlik — sekundiga 100 megabit atrofida), ammo maʼlumotlarni tez uzatish masalasi dolzarbligicha qolmoqda.
Buyumlar interneti maʼlumotlarining asosiy muammosi — qaysi maʼlumotni saqlab qolish va uzatish kerakligini aniqlash. Ular qancha koʻp boʻlsa, ularni kichraytirish va semantik qayta ishlash shuncha muhim, bundan tashqari bu ishlarni iloji boricha maʼlumot uzatgichlarga yaqin boʻlganda qilish kerak. Masalan, Xitoyda millionlab kuzatuv kameralari oʻrnatilgan boʻlib, ularning har biri ulkan hajmdagi maʼlumotlarni hosil qiladi, ammo ularni uzatish va qayta ishlash tarmoqlar oʻtkazuvchanligi bilan cheklangan.
Endilikda eng oddiy kameralarda ham harakatni filtrlash funksiyasi mavjud. Ammo uzatish muhim boʻlmagan statik surat deb nimani hisoblash kerak? Piksellar oʻzgarmaganda (kameraning qarshisida hech narsa harakatlanmaganda)mi? Yoki daydi hayvonlarni odamlardan, mashinalar oqimini “shumaxer”lardan ajratish kerakmi? Unda kamerani sozlash uchun sunʼiy intellektdan u suratning ahamiyatini aniqlashi uchun foydalanish kerak boʻladi. Toʻgʻrisini aytganda, koʻp hollarda bu siyosat masalasi boʻlib qoladi.
Maqolaning 2-qismini bu yerda o‘qing → sinaps.uz/maqola/17634/
Muallif: Irina Smaznevich. Ushbu maqola nplus1.ru saytidagi “Информационные накопления. Как надежно и безопасно хранить данные в облаках” nomli maqolaning tarjimasi.
Muqova surat: freepik.com
